Abstract: Biometric as one of identification or recognition person techniques that based on uniquely part
of human body. Voice one of uniquely human has. Voice signal that come out from different speakers give
different voice pattern. Because of high variations used neural network (NNW)for matching the patterns.
Before voice data is processed using NNW it’s processed using digital processed through feature extraction
phase using discrit wavelet orthogonal base 4 orders with 10 and 15 decomposition rate. The result of
NNW is processed by model decision maker that determine speaker identification. The result of experiment
shows system biometric built can identify as high as 86%
Keywords: Voice Biometric, Wavelet Transformation, Orthogonal Daubenchies, NNW, Decompositione Rate
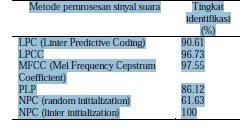
Biometrik merupakan studi tentang metode otomatis untuk mengenali atau mengidentifikasi manusia berdasarkan satu atau lebih bagian tubuh manusia atau kelakuan dari manusia itu sendiri.Dalam dunia teknologi informasi, biometrik relevan dengan teknologi yang digunakan untuk menganalisa fisik dan kelakuan manusia untuk autentifikasi. Contohnya dalam pengenalan fisik manusia yaitu dengan pengenalan sidik jari, retina, iris, pola dari wajah (facial patterns), tanda tangan dan cara mengetik (typing patterns) serta suara. Beberapa hal yang mendorong penggunaan identifikasi secara biometrik adalah biometrik bersifat universal (terdapat pada setiap orang), unik (tiap orang mempunyai ciri khas tersendiri), dan tidak mudah dipalsukan (Xafopoulos, 2001). Dengan teknik biometrik seseorang tidak harus membawa manusia lebih unggul. Suatu teknik yang dibuat dengan memodelkan otak manusia adalah Jaringan Syaraf Tiruan (JST) atau artificial neural network. Seperti pada otak manusia, JST terdiri atas neuronneuron yang saling berhubungan yang dapat bekerja sama satu dengan yang lainnya untuk membentuk suatu sistem. Jaringan syaraf tiruan dapat belajar untuk mengenali suatu pola melalui pembelajaran dan diharapkan dapat memecahkan masalah-masalah yang bersifat nonalgorithmic. Penelitian mengenai identifikasi pembicara telah banyak dilakukan dengan berbagai metode pemrosesan sinyal, seperti Linier Prediction Coding (LPC), Mel Frequency Cepstrum Coefficients (MFCC), Neural Predictive Coding (NPC), dan sebagainya, yang mana keseluruhan metode diatas berbasiskan Transformasi Fourier, dan tingkat identifikasinya telah mencapai 100%, berikut adalah metode-metode yang telah diterapkan dengan tingkat identifikasi yang telah dicapainya, dituangkan dalam bentuk Tabel 1 (Chetouani,
2004).
Tabel 1 Metode-metode yang Digunakan Penelitian Sebelumnya.
Sumber: Universite Pierre&MarieCurie, LA Science A Paris,
2004
Namun, masih banyak kelemahan yang dimiliki transformasi fourier diantaranya, kurang mampu Metode identifikasi pembicara yang merupakan bagian dari pengenalan pembicara (Gambar 1), dapat dibagi ke dalam metode text-independent dan textdependent. Pada sistem text-independent, model
pembicara meng-capture karakteristik ucapan seseorang melalui sinyal ucapan dengan mengabaikan
apa yang diucapkannya, dalam artian katakata yang diucapkan sembarang (bebas). Sebaliknya pada sistem text-dependent, pengenalan identitas pembicaranya didasarkan pada ucapan seseorang dengan kata-kata yang spesifik atau telah disepakati, seperti password, card numbers, kode PIN dan sebagainya(mudry,1997) Semua sistem identifikasi pembicara melalui dua proses penting yaitu feature extraction dan
Semua sistem identifikasi pembicara melalui dua proses penting yaitu feature extraction dan
feature matching. Feature extraction merupakan proses mengekstraksi data hasil akuisisi sehingga dihasilkan data yang berdimensi lebih kecil, yang nantinya digunakan untuk merepresentasikan tiaptiap pembicara. Feature matching menyangkut prosedur aktual yang mengidentifikasi pembicara
yang tidak dikenal dan membandingkan fitur ekstraksi suara yang dimasukan dengan salah satu
dari himpunan pembicara yang telah dikenal. Sistem Identifikasi pembicara juga menyajikan dua sesi yang berbeda, yang pertama menunjukkan pencocokan pola (pattern matching), yaitu proses
pencocokan pola dengan menerima data yang telah diolah oleh ekstrasi ciri sebagai data input, proses tersebut akan mencocokan pola data masukan (input) dengan model referensi dan akan memberikan hasil berupa besarnya skor kesesuaian data input dengan pola-pola referensi yang ada, (f) Pembuatan keputusan yaitu yang akan menerima skor hasil pencocokan pola. Pada sistem identifikasi, pembuatan keputusan akan menentukan identitas pembicara
Seperti terlihat pada Gambar 2. Berdasarkan latar belakang diatas, maka rumusan pertanyaan pada penelitian ini adalah “Bagaimanakah rancangan model prototipe sistem biometrik suara yang dibangun menggunakan transformasi wavelet berbasis orthogonal daubenchies?”, “bagaimanakah implementasi model prototype sistem biometrik suara yang dibangun menggunakan transformasi wavelet berbasis orthogonal daubenchies?”, dan “Berapakah tingkat identifikasi (generalisasi) tertinggi yang dicapai dari sistem biometrik suara yang dibangun menggunakan transformasi wavelet berbasis orthogonal daubenchies?”. Pada dasarnya tujuan dari penelitian ini adalah untuk mendapatkan jawaban dari pertanyaan penelitian yang telah dirumuskan diatas. Sehingga
tujuan penelitian ini adalah (1) diperolehnya rancangan model prototipe sistem biometrik suara yang
Modul training dan modul testing identifikasi dalam satu interface atau satu submenu, sedangkan modul perekaman terdapat dalam submenu yang berbeda (Gambar 4). Pada modul perekaman didalamnya terdapat suatu tahapan praproses (preprocessing) dan data hasil perekaman yang dihasilkan seluruhnya adalah 100 data suara
Pengguna sistem akan mengucapkan kata yang
telah ditentukan sebelumnya yaitu “Ilmu Komputer”. Data audio yang diperoleh akan diubah menjadi bentuk digital (vektor) menggunakan proses sampling dengan perangkat lunak MATLAB 7.0.1. Perekaman dilakukan selama 3 detik (1 detik sama dengan 1000 ms) dengan frekuensi sampling 20kHz (dalam 1 detik diperoleh data sebanyak 22.050 data). Akuisisi data dilakukan pada beberapa tahap. Pada tahap pertama dilakukan akuisisi data untuk pembelajaran sistem. Pada tahap kedua akuisisi data dilakukan untuk menguji sistem identifikasi. Dalam penelitian ini menggunakan frame (n) dengan lebar waktu 30 ms di mana tiap frame menyimpan data sebanyak 661 (hasil pembulatan dari 661,5) sampel dengan overlap (m) 50%, sehingga diperoleh jumlah frame dengan waktu perekaman selama 1 detik sebesar 65 frame (dengan tiap frame mengandung data sebanyak 22050 data). Dengan diperolehnya dalam 1 detik 65 frame maka suatu alat identifikasi seperti pada teknik konvensional. Proses biometrik (selanjutnya menggunakan kata “identifikasi”) dengan suara memiliki keunggulan secara ekonomis dibandingkan dengan karakteristik yang lain. Identifikasi dengan suara hanya membutuhkan alat tambahan berupa mikrofon dan kartu suara, sedangkan karakteristik-karakteristik yang lain misalnya sidik jari atau wajah membutuhkan alat tambahan seperti scanner. Hal ini sedikit banyak dapat menekan biaya pengembangan sistem. Identifikasi melalui suara termasuk dalam masalah nonalgorithmic (Fu, 1994). Walaupun sirkuit digital (komputer) mempunyai kecepatan yang jauh lebih tinggi daripada otak manusia tetapi dalam memproses masalah-masalah nonalgorithmic otak memberikan informasi sinyal dalam domain waktu dan frekuensi secara bersamaan dan menganalisis sinyal yang tidak stationer, untuk itu ingin dikembangkan suatu konsep atau pendekatan lain dalam pemrosesan sinyal tanpa berbasiskan transformasi fourier yaitu dengan transformasi wavelet. Transformasi Wavelet merupakan sarana yang mulai populer untuk pemrosesan sinyal, seperti citra dan suara, dan transformasi ini belum banyak diaplikasikan untuk analisis suara, khususnya untuk identifikasi pembicara menggunakan teks berbahasa Indonesia. Dalam praktek, Transformasi Wavelet digunakan untuk ekstraksi ciri dalam sistem pengenalan suara karena mempunyai karakter khusus yang sesuai untuk analisis sinyal, termasuk sinyal suara. Transformasi wavelet sinyal suara menghasilkan resolusi waktu yang baik pada frekuensi tinggi dalam menentukan
lokasi awal suara dan parameterisasi ciri suara durasi pendek serta mampu menganalisis sinyal diskontinu (non stationary) secara akurat (Krisnan, 1994). Pengenalan pembicara dapat diklasifikasikan ke dalam tiga tahap yaitu identifikasi, deteksi dan verifikasi. Identifikasi pembicara merupakan proses untuk menentukan identitas pembicara melalui suara yang telah diucapkan, sedangkan deteksi pembicara merupakan proses penemuan suara pembicara dari sekumpulan suara, dan verifikasi pembicara merupakan proses untuk memverifikasi kesesuaian suara pembicara dengan identitas yang diklaim oleh pembicara. Pengenalan pembicara lebih menitikberatkan pada pengenalan suara pembicara dan tidak pada pengenalan ucapan pembicara (Ho, 1998) . sesi pendaftaran (enrollment sessions) atau fase training, sedangkan yang kedua menunjukkan sesi operasi atau fase testing. Di dalam fase training, tiap pembicara yang telah terdaftar memasukkan contoh (sampel) suaranya sehingga sistem dapat mulai dibangun atau dilatih berdasarkan reference model pembicara tadi. Secara umum sistem identifikasi pembicara mempunyai tahapan sebagai berikut dengan diagram
bloknya diilustrasikan pada Gambar 2 (Campbell,1997), (a) akuisisi data suara digital, yaitu proses untuk mengakuisisi ucapan pembicara (dalam sinyal analog) dan mengubahnya menjadi sinyal digital. Sinyal digital yang terbentuk berupa suatu vektor yang merepresentasikan suara pembicara, (b) frame blocking dan windowing, yaitu frame blocking merupakan proses segmentasi sinyal suara digital yang telah diakuisisi ke dalam durasi tertentu, sedangkan frame windowing adalah proses yang bertujuan untuk meminimalkan diskontinuitas (nonstationary) sinyal pada bagian awal dan akhir sinyal
suara, (c) ekstraksi ciri (feature extraction), yaitu mengekstrak data hasil akuisisi sehingga dihasilkan
data yang berdimensi lebih kecil tanpa merubah karakteristik sinyal suara, (d) pembentukan model
referensi pembicara, merupakan tahapan pembelajaran dan akan membentuk suatu model referensi
agar sistem dapat mengenali pembicara. Tahap ini memerlukan data berupa vektor-vektor ciri hasil dari ekstraksi ciri yang mencakup seluruh pembicara, model referensi yang terbentuk akan digunakan dalam pencocokan pola, pembentukan model referensi pembicara merupakan tahapan khusus yang dilakukan pada waktu awal sebelum sistem siap digunakan, tahap ini hanya dilakukan sekali dan setelah dilakukan maka sistem siap untuk digunakan, (e) dibangun menggunakan transformasi wavelet
berbasis orthogonal daubenchies, (2) diimplementasikannya model prototipe sistem biometrik suara
yang dibangun menggunakan transformasi wavelet berbasis orthogonal daubenchies serta 3).
Diperolehnya tingkat identifikasi (generlisasi) tertinggi yang dicapai dari sistem biometrik suara yang dibangun menggunakan transformasi wavelet berbasis orthogonal daubenchies. Penelitian ini diharapkan dapat digunakan untuk melakukan identifikasi seseorang melalui kata-kata
yang diucapkan orang tersebut. Hasil yang diberikan pada identifikasi berupa identitas pengguna sistem. Sistem ini antara lain bermanfaat untuk melakukan identifikasi semacam aplikasi absensi, kontrol akses untuk fasilitas tertentu, remote akses untuk jaringan komputer, forensik, dan lain-lain, serta untuk pengembangan ilmu pengetahuan khususnya dalam pengolahan sinyal suara.
Metode Penelitian
Perancangan model sistem dibangun untuk memudahkan pengguna di dalam pengolahan data dan
melihat hasil yang diperoleh dari model sistem tersebut. Sistem yang akan dikembangkan disajikan
pada Gambar 3. Sistem tersebut terbagi ke dalam tiga modul yaitu modul perekaman, modul training
(pelatihan), dan modul testing (pengujian) identifikasi.
perekaman yang dilakukan selama 3 detik menghasilkan 195 frame. Proses ektraksi ciri pada penelitian ini, adalah data yang telah terbagi ke dalam frame-frame dan telah dikalikan dengan Hamming window. Masing-masing dari proses ekstraksi ciri diatas akan menghasilkan koefisien-koefisien (koefisien detail dan perkiraan) yang diperoleh dari hasil dekomposisi pada level 10 dan 15. Pada penelitian ini koefisien yang diambil sebagai masukan ke proses selanjutnya adalah koefisien yang dihasilkan dari frekuensi rendah yaitu koefisien perkiraan (approximation) karena bagian penting dari suatu sinyal terletak pada frekuensi tersebut, yang mampu memberikan identitas dari suatu sinyal. Koefisie yang dihasilkan akan membentuk suatu vektor. Algoritma berikut adalah untuk mencari koefisien detail dan perkiraan pada proses multiple dekomposisi:
- Sinyal yang masuk difilter ke dalam sinyal frekuensi rendah (low-pass filter) dan sinyal frekuensi tinggi (high-pass filter)
- Lakukan downsampling pada ke dua sinyal tersebut
- Low-pass frekuensi hasil downsampling selanjutnya melalui proses seperti pada tahap pertama
- Lakukan ulang sampai pada level yang diinginkan Pembentukan model referensi pembicara dan pencocokan pola dilakukan menggunakan JST Propagasi Balik. Arsitektur yang digunakan untuk
JST Propagasi Balik adalah Multi Layer Perceptron, dengan satu lapisan tersembunyi. JST terlebih dahulu dilatih untuk membentuk model referensi pembicara. Setelah tahap pembelajaran selesai dilakukan, JST dapat digunakan untuk melakukan pencocokan pola. Pada proses identifikasi, pembuatan keputusan
Diposting oleh
cerdaas

{kind=link}
0 komentar:
Posting Komentar